HDFS
如何学习大数据?
大数据生态有什么?
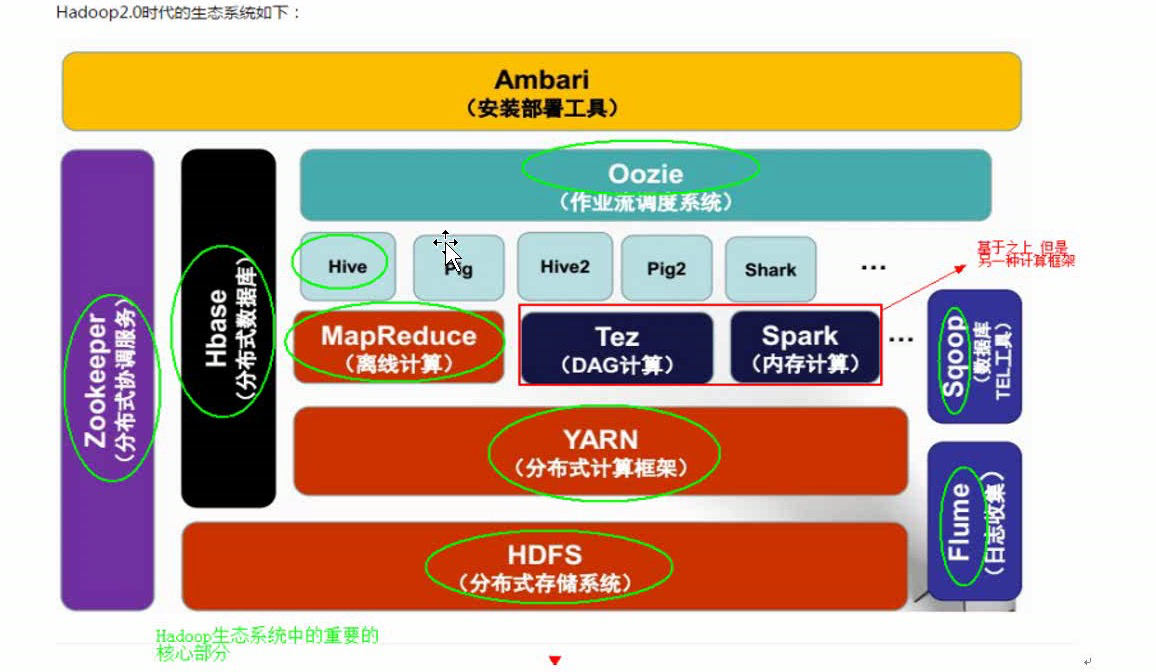
共同点是:都是分布式的。 分布式就是将庞大的数据,复杂的业务分发到不同的计算机节点和服务器上进行处理。
为什么使用分布式呢?要从大数据的角度思考🤔 🎉 1.效率高,处理快 2.单点限制,给单机解压 3.可扩展,添加更多的节点 4.安全稳定,一个节点宕机,另一个节点可以接替。
大数据架构层面看问题,。
分布式计算就是将庞大的数据,复杂的业务分发到不同的计算机节点和服务器上进行处理。 发展:03年Google 发表三篇论文,分别是 GFS,mapreduce,bigtable的思想,分别对应后来出现的 HDFS,mapreduce,Hbase 06年 Docu cutting 推出 Hadoop,现在就职于 Cloudra 公司。 阿里飞天2.0完成重大如破!!!
等等上述这些都是大数据的基石,这个时代研究大数据是很有意义的。时代在进步...
HDFS 是什么?
它是一个__分布式文件存储系统,__全称是 Hadoop Distributed File System 。 为什么会出现这个呢?想象一个场景,数据随着业务的增长飞快的积累,达到了PB甚至更大的量级,这时候受网络带宽和单机节点的资源限制的影响,海量的数据无法进行存储,如何存储,万一数据丢了怎么办?这一系列问题,在 HDFS 中都将迎刃而解。HDFS 就是解决海量数据的存储问题。百度网盘就是一个现实的例子,它的成功离不开 分布式存储技术。
科普: PB = 1024TB TB = 1024GB GB = 1024MB MB = 1024KB
假设这里有 一个带宽为 4000M 的网络,带宽是以 bit(比特)表示,而电信,联通,移动等运营商在推广的时候往往忽略了这个单位。 所以实际处理处理速度是 4000/8=500m/s
传输 1TB 的数据,大概是 2097秒 约等于 34 分钟。 传输 1PB 的数据 ,大概是 596 小时 约等于 24 天。这还是在没有其他因素的影响下。注意 PB 级别的数据是大数据的入门级别的数据。可见处理海量数据,单机是很难高效的进行的,需要利用分布式来存储和计算海量数据。
HDFS 的优缺点
优点:
- 处理海量数据,TB , PB ...
- 支持处理百万规模以上的文件数量, 10k+节点
- 适合批处理 ,移动计算而非数据,数据位置暴露给计算框架
- 可构建在廉价机器上
- 可靠性高,多个副本
- 自动创建多个副本,副本丢失后自动恢复,高容错性
缺点:
- 不支持毫秒级别
- 吞吐量达但受限于延迟
- 不允许修改文件(其实本身支持,但不这么做,为了性能)
HDFS 1.x 架构图
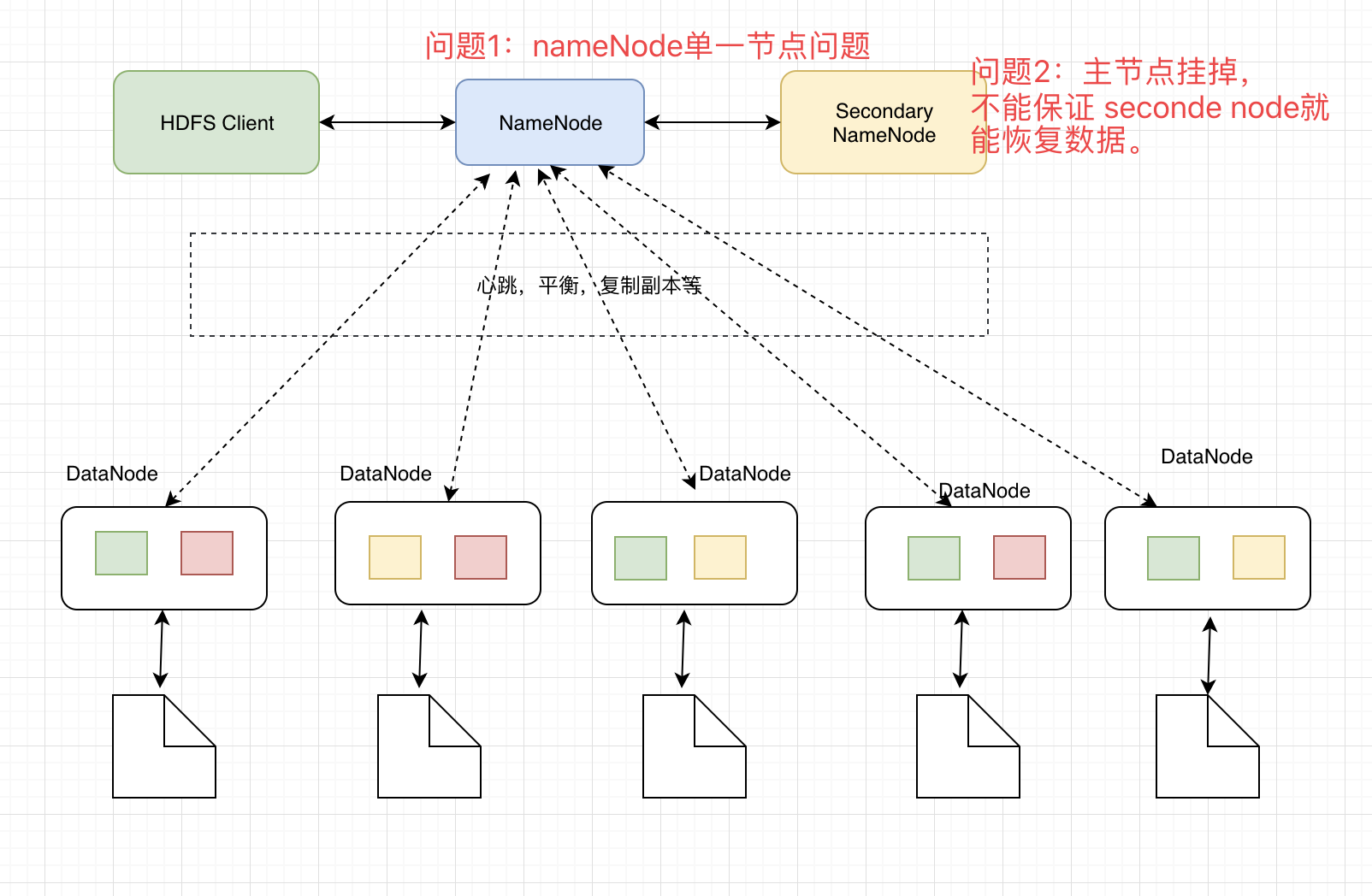
上述红字部分是这个架构存在的问题,后面还提到__ fsimage__ 太大之后消耗内存的问题。
由上图可见,HDFS主要的部分有 NameNode , DateNode , Secondeary Namenode
HDFS 功能模块详解
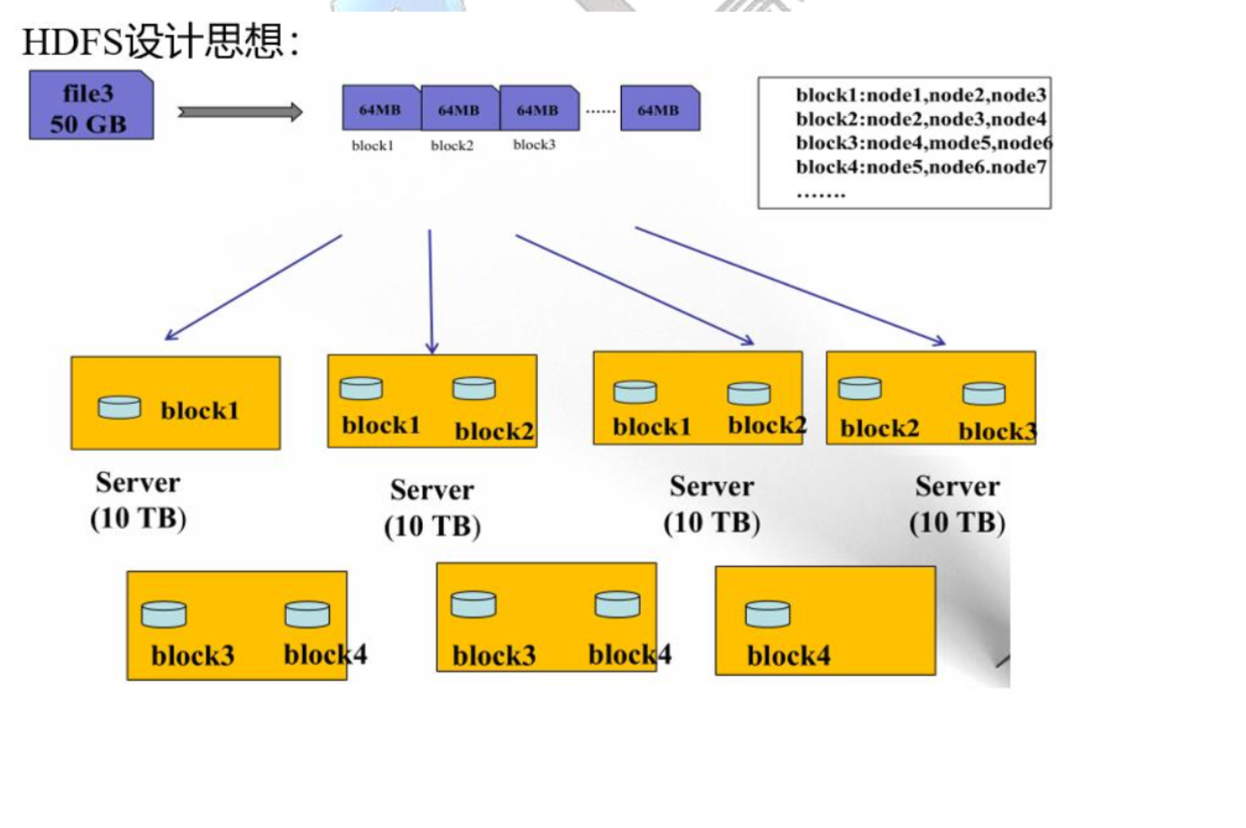
HDFS 数据存储模型(逻辑上)
文件被__线性切分__为固定大小的 block 块。通过偏移量(offset)进行标记。 1.x版本的默认 block 块为 64 M 2.x版本的默认 block 块为 128 M
存储方式
按__固定大小__切分为若干个 block ,存储到不同的节点上。 默认情况下,每个 block 都有额外的两个副本,共三份。 副本数不能大于节点数,(同一个节点就出现相同的副本了,没有意义)
文件上传时,可以通过 HDFS 客户端设置 文件的副本数和 block 大小,该文件一旦上传之后,副本数可以修改,但是 block 的大小就不能改了。
NameNode
简称 NN , 主要是干什么的呢?
观察之前的结构图,也可以看出,不管是文件的读取和写入都是要经过 NameNode 节点的,而且 NameNode 节点接受来自 DataNode 的心跳数据,而且还会存储文件的元数据(文件大小,归属,权限,偏移量列表即说明一个完整的文件包含哪些 block )
综上,NameNode 主要干这样事情:
- 接受客户端的读、写
- 接收 DN 汇报 block 列表
- 保存元数据,元数据是基于内存的。数据包括文件的大小,归属,偏移量列表等
- block 的位置信息,在启动的时候上报给 NN,并且动态更新。一般是3秒一次
说明:
NameNode 如果10分钟没有收到 DN 的汇报,就会认为这个节点 lost 了,然后把缺失的副本在别的节点上增加一份。
NameNode 启动之后,会加载元数据到内存中,也会创建一份镜像文件 fsimage.
block 位置信息不会保存到 fsimage
eidts 记录对元数据的操作日志。
Secondary NameNode
它的主要工作主要是帮助NN合并 edits 和元数据,减少 NN 启动时间。
执行合并的时间和机制:
- 根据配置文件配置时间间隔:fs.checkppint.period , 默认为 3600 秒
- 根据配置文件设置 edits log 的大小,fs.checkpoint.size 默认为 64 MB
合并流程:图示
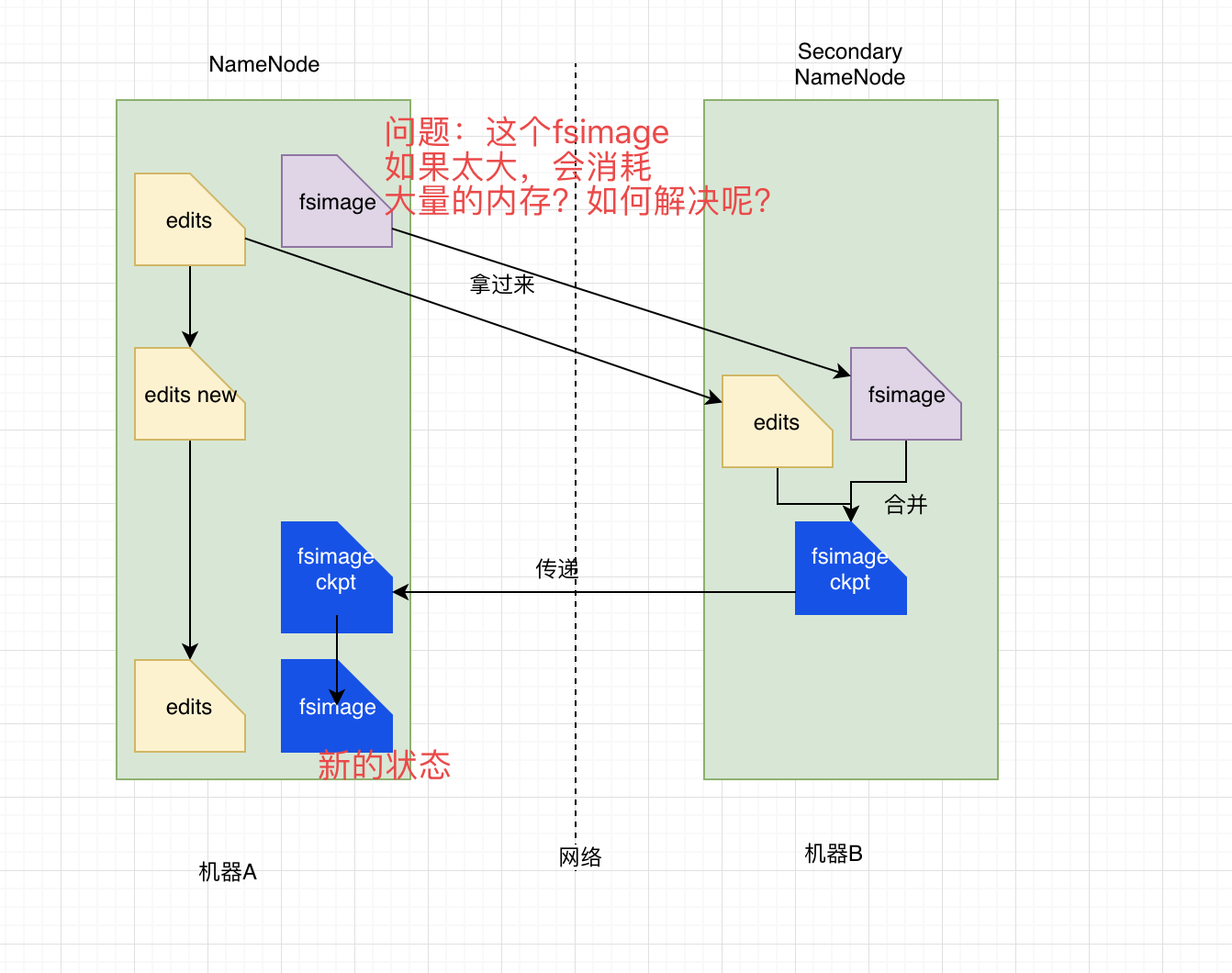
步骤一:__SSN __在一个 checkpoint 时间点和 __NameNode __进行通信,请求 NameNode 停止使用 edits 文件记录相关操作而是暂时将新的 Write 操作写到新的文件 edits.new 来。
步骤二:SSN 通过 HTTP GET 的方式从 __NameNode __中将 __fsimage__和__edits __文件下载回来本地目录中。
步骤三:SSN中合并 edits 和 fsimage 。SSN 将从 NameNode 中下载回来的 fsimage 加载到内存中,然后逐条 执行 edits 文件中的各个操作项,使得加载到内存中的 fsimage 中包含 edits 中的操作,这个过程就是所谓的合并了。
步骤四:在 SSN 中合并完 fsimage 和 edits 文件后,需要将新的 fsimage 回传到 NameNode 上,这个是通过__HTTP POST __方式进行的。
步骤五:__NameNode __将从 SSN 接收到的新的 fsimage 替换掉旧的 fsimage 。同时将 edits.new 文件转换为通常的 edits 文件,这样 edits 文件的大小就得到减少了。SSN 整个合并以及和 NameNode 的交互过程到这里已经结束。
一个亿的 block 的元数据会占用138G的内存。可见,元数据太大,会大量占用服务器的内存资源
__DataNode __
就是用来存储数据的。逻辑上分为各个block 块
这里有一个 block 块的放置策略:
- 第一个副本,如果在集群内部会放到上传的这台服务器的 DN 上。如果是集群外,则会随机找一个空闲的机器。
- 第二个副本,放置在与第一个副本 不同机架 的节点上。
- 第三个副本,放置在与第二个副本 相同机架 的 不同 节点上。
- 更多 副本,随机
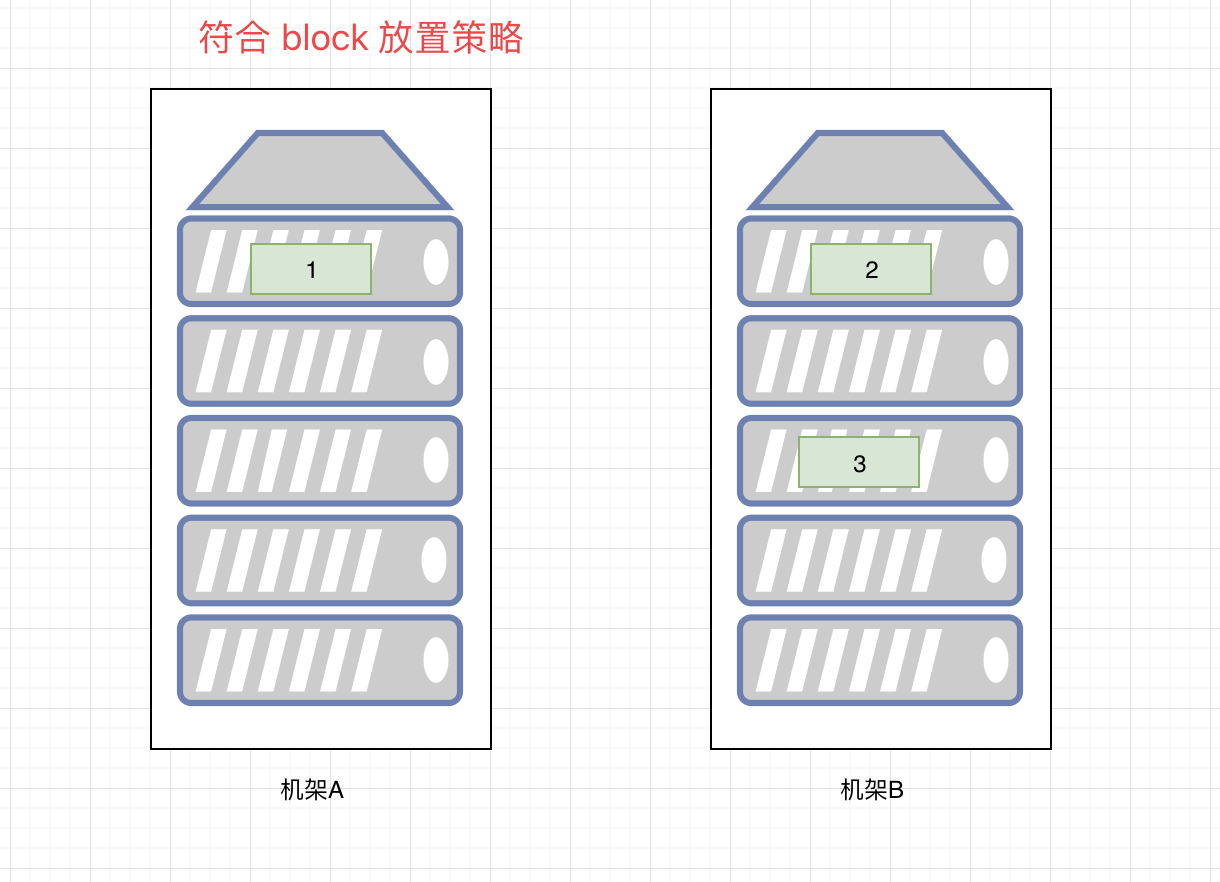
机架,这种结构的多为功能型服务器。机房里面可以见到,不同网段,Hadoop源码里面提供了感知机架(机架感应)的代码。
HDFS的读流程
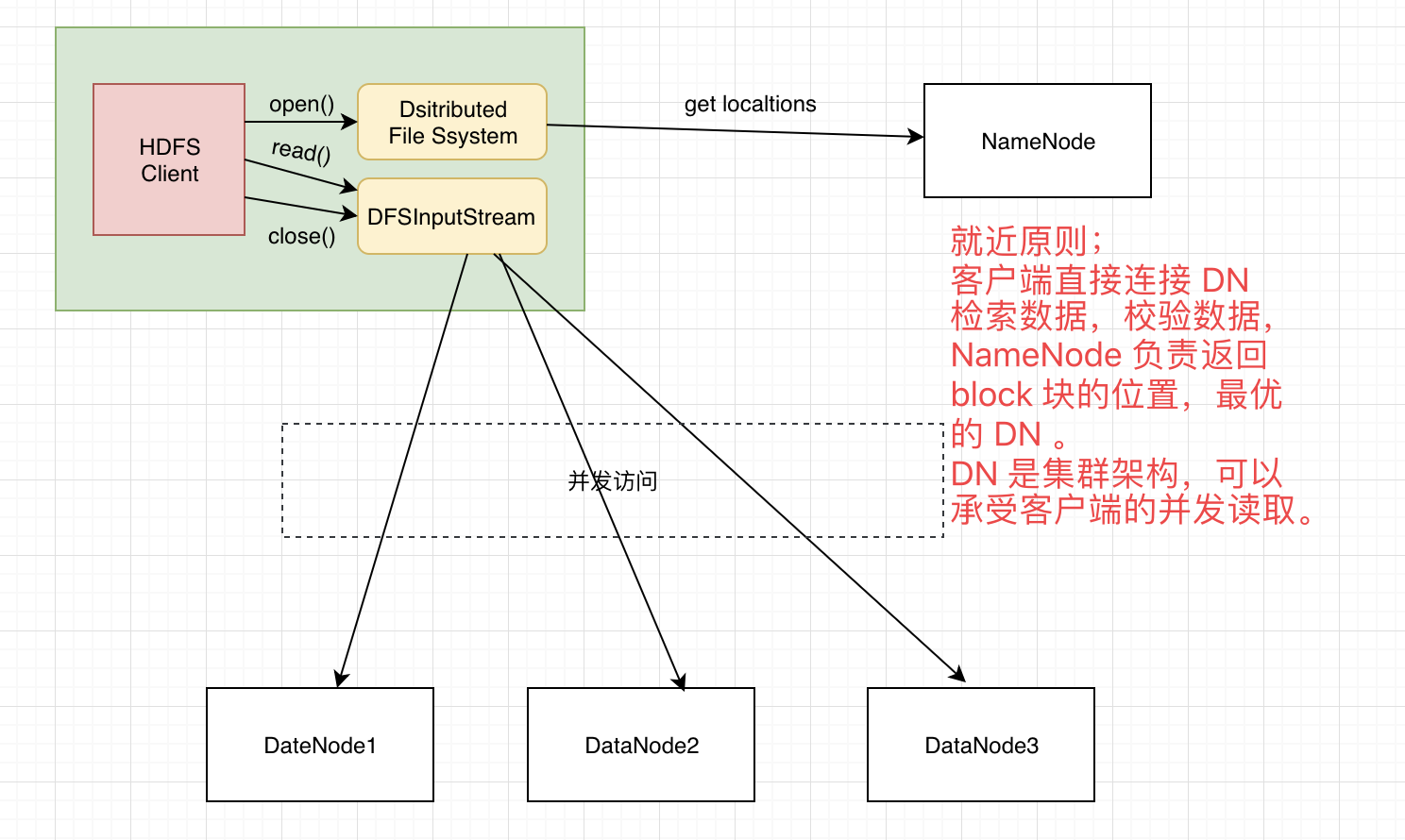
角色:HDFS Client , NameNode, DateNode
1,首先 HDFS 调用 FileSystem 对象的 Open 方法获取一个 DistributedFileSystem 实例; 2,DistributedFileSystem 通过 RPC协议 获取第一批 block localtions(第一批 block 块的位置),同一个 block 和副本都会返回位置信息,这些位置信息按照 hadoop 的拓扑结构给这些位置排序,就近原则。 3.前两部会生成一个 FSDataInputStream ,该对象会被封装 DFSInputStream 对象,DFSInputStream 可以方便的管理 datanode 和 namenode 数据流。客户端调用 read 方法,DFSInputStream 最会找出离客户端最近的 datanode 并连接。 4.数据从 datanode 源源不断的流向客户端。这些操作对客户端来说是透明的,客户端的角度看来只 是读一个持续不断的流。
5.如果第一批 block 都读完了, DFSInputStream 就会去 namenode 拿下一批 block 的 locations,然后继续读,如果所有的块都读完,这时就会关闭掉所有的流。如果在读数据的时候, DFSInputStream 和 datanode的通讯发生异常,就会尝试正在读的 block 的排序第二近的datanode,并且会记录哪个 datanode 发生错误,剩余的blocks 读的时候就会直接跳过该 datanode。 DFSInputStream 也会检查 block 数据校验和,如果发现一个坏的 block ,就会先报告到 namenode 节点,然后DFSInputStream 在其他的 datanode 上读该 block 的镜像。该设计就是客户端直接连接 datanode 来检索数据并且namenode 来负责为每一个 block 提供最优的 datanode,namenode 仅仅处理 block location 的请求,这些信息都加载在 namenode 的内存中,hdfs 通过 datanode 集群可以承受大量客户端的并发访问。
RPC 跨越了传输层和应用层。RPC 使得开发包括网络分布式多程序在内的应用程序更加容易。
HDFS的写流程
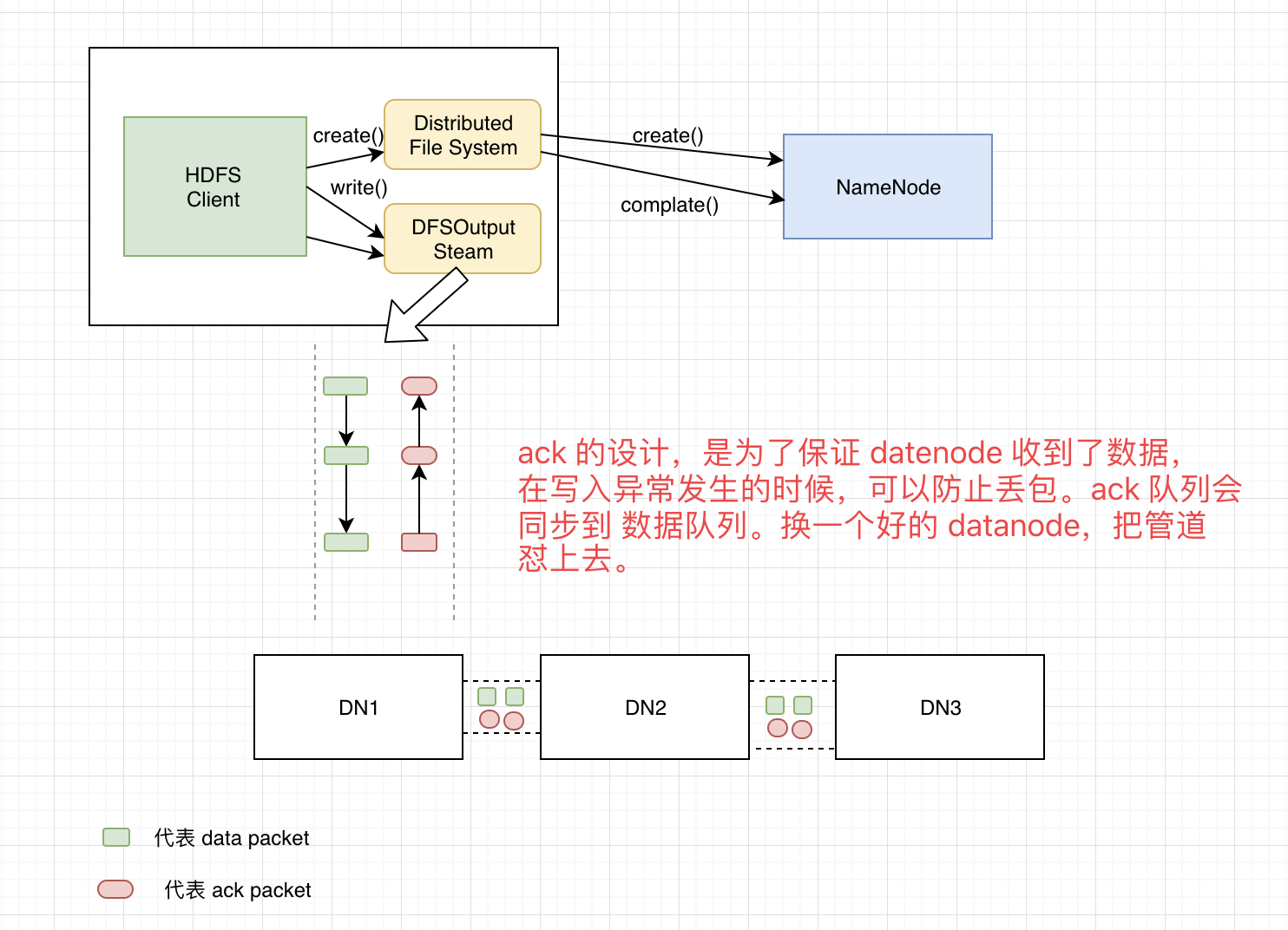
1.客户端通过调用 DistributedFileSystem 的 create 方法创建新文件。
2.DistributedFileSystem 通过 RPC 调用 namenode 去创建一个没有 blocks 关联的新文件,创建前, namenode 会做各种校验,比如文件是否存在,客户端有无权限去创建等。如果校验通过, namenode 就会记录下新文件,否则就会抛出IO异常。
3.前两步结束后,会返回 FSDataOutputStream 的对象,与读文件的时候相似,FSDataOutputStream 被封装成DFSOutputStream。 DFSOutputStream 可以协调 namenode 和 datanode。客户端开始写数据到 DFSOutputStream,DFSOutputStream 会把数 据切成一个个小的 packet,然后排成队列 data quene。
4.DataStreamer 会去处理接受 data quene,它先询问namenode 这个新的 block 最适合存储的在哪几个 datanode。
里(比如重复数是 3,那么就找到 3 个最适合的 datanode),把他们排成一个管道 pipeline 输出。DataStreamer 把packet 按队列输出到管道的第一个 datanode 中,第一个datanode 又把 packet 输出到第二个 datanode 中,以此类推。
5.DFSOutputStream 还有一个对列叫 ack quene,也是由 packet 组成等待 datanode 的收到响应,当 pipeline 中的 datanode 都表示已经收到数据的时候,这时 ack quene才会把对应的 packet 包移除掉。 如果在写的过程中某个datanode 发生错误,会采取以下几步:
pipeline 被关闭掉;
为了防止防止丢包。ack quene 里的 packet 会同步到 data quene 里;创建新的 pipeline 管道怼到其他正常 DN上
剩下的部分被写到剩下的两个正常的 datanode 中;
namenode 找到另外的 datanode 去创建这个块的复制。当然,这些操作对客户端来说是无感知的。
6.客户端完成写数据后调用 close 方法关闭写入流。深入 DFSOutputStream 内部原理
打开一个 DFSOutputStream 流,Client 会写数据到流内部的一个缓冲区中,然后数据被分解成多个 Packet,每个Packet 大小为 64k 字节,每个 Packet 又由一组 chunk 和这组 chunk 对应的 checksum 数据组成,默认 chunk 大小为 512字节,每个 checksum 是对 512 字节数据计算的校验和数据。
===》当 Client 写入的字节流数据达到一个 Packet 的长度,这个 Packet 会被构建出来,然后会被放到队列dataQueue 中,接着 DataStreamer 线程会不断地从dataQueue 队列中取出 Packet,发送到复制 Pipeline 中的第一个 DataNode 上,并将该 Packet 从 dataQueue 队列中移到 ackQueue 队列中。ResponseProcessor 线程接收从Datanode 发送过来的 ack,如果是一个成功的 ack,表示复制 Pipeline 中的所有 Datanode 都已经接收到这个 Packet,ResponseProcessor 线程将 packet 从队列 ackQueue 中删除。
====》 在发送过程中,如果发生错误,错误的数据节点会被移除掉,ackqueue 数据块同步到 dataqueue 中,然后重新创建一个新的 Pipeline,排除掉出错的那些 DataNode节点,接着 DataStreamer 线程继续从 dataQueue 队列中发送 Packet。
下面是 DFSOutputStream 的结构及其原理,如图所示:
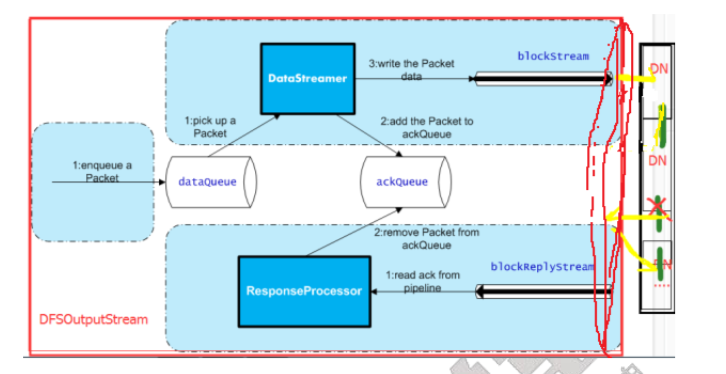
注意:客户端执行 write 操作后,写完的 block 才是可见的,正在写的 block 对客户端是不可见的,只有调用 sync 方法,客户端才确保该文件的写操作已经全部完成,当客户端调用 close 方法时,会默认调用 sync 方法。是否需要手动调用取决你根据程序需要在数据健壮性和吞吐率之间的权衡。
HDFS 的文件权限和安全模式
安全模式
- namenode 启动的时候,首先将映像文件(fsimage)载入内存,并执行编辑日志(edits)中的各 项操作。
- 一旦在内存中成功建立文件系统元数据的映射,则创建一个新的fsimage 文件(这个操作不需要 SecondaryNameNode)和一个空的编辑日志。
- 此刻 namenode 运行在安全模式。即 namenode 的文件系统对于客服端来说是只读的。(显示 目录,显示文件内容等。写、删除、重命名都会失败)。
- 在此阶段 Namenode 收集各个 datanode 的报告,当数据块达到最小副本数以上时,会被认为是“安全”的, 在一定比例(可设置)的数据块被确定为“安全”后,再过若干时间,安全模式结束
- 当检测到副本数不足的数据块时,该块会被复制直到达到最小副本数,系统中数据块的位 置并不是由 namenode 维护的,而是以块列表形式存储在 datanode 中

退出安全模式:hdfs namenode -safemode leave
HDFS 命令操作
hdfs dfs -put file /input
file是要上传的文件,/input 是文件上传到 hdfs 的路径。
hdfs dfs -rm -rf file /input
删除文件
hdfs dfs -mkdir -p /input
创建目录
其他的可以查看 help