MR的原理和运行流程
Map的运行过程
以HDFS上的文件作为默认输入源为例(MR也可以有其他的输入源)

block是HDFS上的文件块,split是文件的分片(逻辑划分,不包含具体数据,只包含这些数据的位置信息)。
- 一个split包含一个或多个block,默认是一对一的关系。
- 一个split不包含两个文件的block, 不会跨越file边界,也就是说一个split是不会跨文件进行划分的。
当分片完成后,MR程序会将split中的数据以K/V(key/value)的形式读取出来,然后将这些数据交给用户自定义的Map函数进行处理。
- 一个Map处理一个split。
用户用Map函数处理完数据后将处理后,同样将结果以K/V的形式交给MR的计算框架。
MR计算框架会将不同的数据划分成不同的partition,数据相同的多个partition最后会分到同一个reduce节点上面进行处理,也就是说一类partition对应一个reduce。
Map默认使用Hash算法对key值进行Hash计算,这样保证了相同key值的数据能够划分到相同的partition中,同时也保证了不同的partition之间的数据量时大致相当的,参考链接
一个程序中Map和Reduce的数量是有split和partition的数据决定的。
Reduce处理过程

- Map处理完后,reduce处理程序在各个Map节点将属于自己的数据拷贝到自己的内存缓冲区中
- 最后将这些数据合并成一个大的数据集,并且按照key值进行聚合,把聚合后的value值作为一个迭代器给用户使用。
- 用户使用自定义的reduce函数处理完迭代器中的数据后,一般把结果以K/V的格式存储到HDFS上的文件中。
Shuffle过程
- 在上面介绍的MR过程中,还存在一个shuffle过程,发生与Map和Reduce之中。

Map中的shuffle
- Collec阶段键数据放在环形缓冲区,唤醒缓冲区分为数据区和索引区。
- sort阶段对在统一partition内的索引按照key值排序。
- spill(溢写)阶段根据拍好序的索引将数据按顺序写到文件中。
- Merge阶段将Spill生成的小文件分批合并排序成一个大文件。
- Reduce中的shuffle
- Copy阶段将Map段的数据分批拷贝到Reduce的缓冲区。
- Spill阶段将内存缓冲区的数据按照顺序写到文件中。
- Merge阶段将溢出文件合并成一个排好序的数据集。
- Combine优化
整个过程中可以提前对聚合好的value值进行计算,这个过程就叫Combine。
Combine在Map端发生时间
- 在数据排序后,溢写到磁盘前,相同key值的value是紧挨在一起的,可以进行聚合运算,运行一次combiner。
- 再合并溢出文件输出到磁盘前,如果存在至少3个溢出文件,则运行combiner,可以通过min.num.spills.for.combine设置阈值。
Reduce端
- 在合并溢出文件输出到磁盘前,运行combiner。
Combiner不是任何情况下都适用的,需要根据业务需要进行设置。
MR运行过程

- 一个文件分成多个split数据片。
- 每个split由多一个map进行处理。
- Map处理完一个数据就把处理结果放到一个环形缓冲区内存中。
- 环形缓冲区满后里面的数据会被溢写到一个个小文件中。
- 小文件会被合并成一个大文件,大文件会按照partition进行排序。
- reduce节点将所有属于自己的数据从partition中拷贝到自己的缓冲区中,并进行合并。
- 最后合并后的数据交给reduce处理程序进行处理。
- 处理后的结果存放到HDFS上。
- MR运行在集群上:YARN(Yet Another Resource Negotiator)
 __ ResourceManager负责调度和管理整个集群的资源__
__ ResourceManager负责调度和管理整个集群的资源__
* 主要职责是调度,对应用程序的整体进行资源分配
* Nodemanager负责节点上的计算资源,内部包含Container, App Master,管理Container生命周期,资源使用情况,节点健康状况,并将这些信息回报给RM。
* Container中包含一些资源信息,如cpu核数,内存大小
* 一个应用程序由一个App Master管理,App Master负责将应用程序运行在各个节点的Container中,App Master与RM协商资源分配的问题。
* ## <a name="uo0fvt"></a>MapReduce On Yarn

* MR程序在客户端启动,客户端会向RM发送一个请求。
* RM收到请求后返回一个AppID给客户端。
* 然后客户端拿着AppID,用户名,队列,令牌向RM发出资源请求。
* 客户端这时会将程序用到的jar包,资源文件,程序运行中需要的数据等传送到HDFS上。
* RM接收到客户端的资源请求后,分配一个container0的资源包,由NodeManager启动一个AppMaster。
* RM将集群的容量信息发送给AppMaster,AppMaster计算这个程序需要的资源量后,根据需要想RM请求更多的container。
* 最后由各个NodeManager在节点上启动MapTask和ReduceTask。
Yarn && Job
上面的 Yarn 管理 MR 任务是不是比较粗略,下面我将介绍比较详细的处理流程:
这也是今日头条的一个面试题,引发的思考:
MR 任务为例,讲一下 Yarn 的整个过程。
Yarn 中的主要组件包括:Resourcemanager,ApplicationMaster, NodeManager。
Resourcemanager:每个Hadoop集群只会有一个ResourceManager(如果是HA的话会存在两个,但是有且只有一个处于active状态),启动每一个 Job 所属的 ApplicationMaster,另外监控ApplicationMaster 以及NodeManager 的存在情况,并且负责协调计算节点上计算资源的分配。ResourceManager 内部主要有两个组件:
- Scheduler:这个组件完全是插拔式的,用户可以根据自己的需求实现不同的调度器,目前YARN提供了FIFO、容量以及公平调度器。这个组件的唯一功能就是给提交到集群的应用程序分配资源,并且对可用的资源和运行的队列进行限制。Scheduler并不对作业进行监控;
- ApplicationsManager :这个组件用于管理整个集群应用程序的 application masters,负责接收应用程序的提交;为application master启动提供资源;监控应用程序的运行进度以及在应用程序出现故障时重启它。
ApplicationMaster:每个 Job 都有对应一个 ApplicationMaster ,并且负责运行 mapreduce 任务,并负责报告任务的状态。ApplicationMaster是应用程序级别的,每个ApplicationMaster管理运行在YARN上的应用程序。YARN 将 ApplicationMaster看做是第三方组件,ApplicationMaster负责和ResourceManager scheduler协商资源,并且和NodeManager通信来运行相应的task。ResourceManager 为 ApplicationMaster 分配容器,这些容器将会用来运行task。ApplicationMaster 也会追踪应用程序的状态,监控容器的运行进度。当容器运行完成, ApplicationMaster 将会向 ResourceManager 注销这个容器;如果是整个作业运行完成,其也会向 ResourceManager 注销自己,这样这些资源就可以分配给其他的应用程序使用了。
NodeManager:负责启动和管理节点的容器。NodeManager是YARN中每个节点上的代理,它管理Hadoop集群中单个计算节点,根据相关的设置来启动容器的。NodeManager会定期向ResourceManager发送心跳信息来更新其健康状态。同时其也会监督Container的生命周期管理,监控每个Container的资源使用(内存、CPU等)情况,追踪节点健康状况,管理日志和不同应用程序用到的附属服务(auxiliary service)。
Container: Container是与特定节点绑定的,其包含了内存、CPU磁盘等逻辑资源。不过在现在的容器实现中,这些资源只包括了内存和CPU。容器是由 ResourceManager scheduler 服务动态分配的资源构成。容器授予 ApplicationMaster 使用特定主机的特定数量资源的权限。ApplicationMaster 也是在容器中运行的,其在应用程序分配的第一个容器中运行。
必须牢记yarn只是一个资源管理的框架,并不是一个计算框架,计算框架可以运行在yarn上。我们所能做的就是向RM申请container,然后配合NM一起来启动container。
下面是请求资源和分配资源的流程:
1.客户端向 ResourceManager 发送 job 请求,客户端产生的 RunJar 进程与 ResourceManager 通过 RPC 通信。 2.ResourceManager 向客户端返回 job 相关资源的提交路径以及 jobID。 3.客户端将 job 相关的资源提交到相应的共享文件夹下。 4.客户端向 ResourceManager 提交 job 5.ResourceManager 通过__调度器__在 NodeManager 创建一个容器,并且在容器中启用MRAppmaster 进程,该进程由 ResourceManager 启动。 6.该 MRAppmaster 进程对作业进行初始化,创建多个对象对作业进行跟踪。 7.MRAppmaster 从文件系统获取计算得到输入分片,只获取切片信息,不需要jar等资源,为每个分片创建一个 map 以及指定数量的 reduce 对象,之后 MRAppmaster 决定如何运行构成 mapreduce 的各个任务。 8.若作业很大,MRAppmaster 为所有的 map 任务和reduce 任务向 ResourceManger 发起申请容器的请求,请求中包含 map 任务的数据本地化信息以及数据分片等信息。 9.ResourceManager 为任务分配了容器之后,MRAppmaster 就通过 与 NodeManger 通信启动容器,由 MRAppmaster 负责分配在哪些 NodeManager 负责分配在哪些 NodeManager 上运行map (即 yarnchild 进程)和reduce 任务。 10.运行 mao 和 reduce 任务的 NodeManager 从共享系统中获取 job 的相关县,包括 jar 文件,配置文件等。 11.关于查询状态,不经过 reourcemanager ,而是任务周期性的 MRAppmaster 汇报状态以及进度,客户端每秒通过查询一次 MRAppmaster 来更新状态和信息。
上面可以很乱,重点是辅助理解细节,认知到位了,无关细节了吧。
下面总结一下,大概的流程:
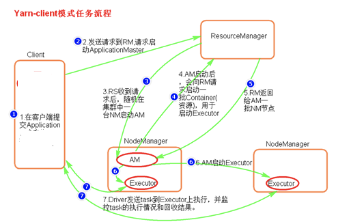
流程大致如下: · client客户端向yarn集群(resourcemanager)提交任务 · resourcemanager选择一个node创建appmaster · appmaster根据任务向rm申请资源 · rm返回资源申请的结果 · appmaster去对应的node上创建任务需要的资源(container形式,包括内存和CPU) · appmaster负责与nodemanager进行沟通,监控任务运行 · 最后任务运行成功,汇总结果。 其中Resourcemanager里面一个很重要的东西,就是调度器Scheduler,调度规则可以使用官方提供的,也可以自定义。
评价交流
欢迎留下的你的想法~