Kafka
1.Kafka 零拷贝
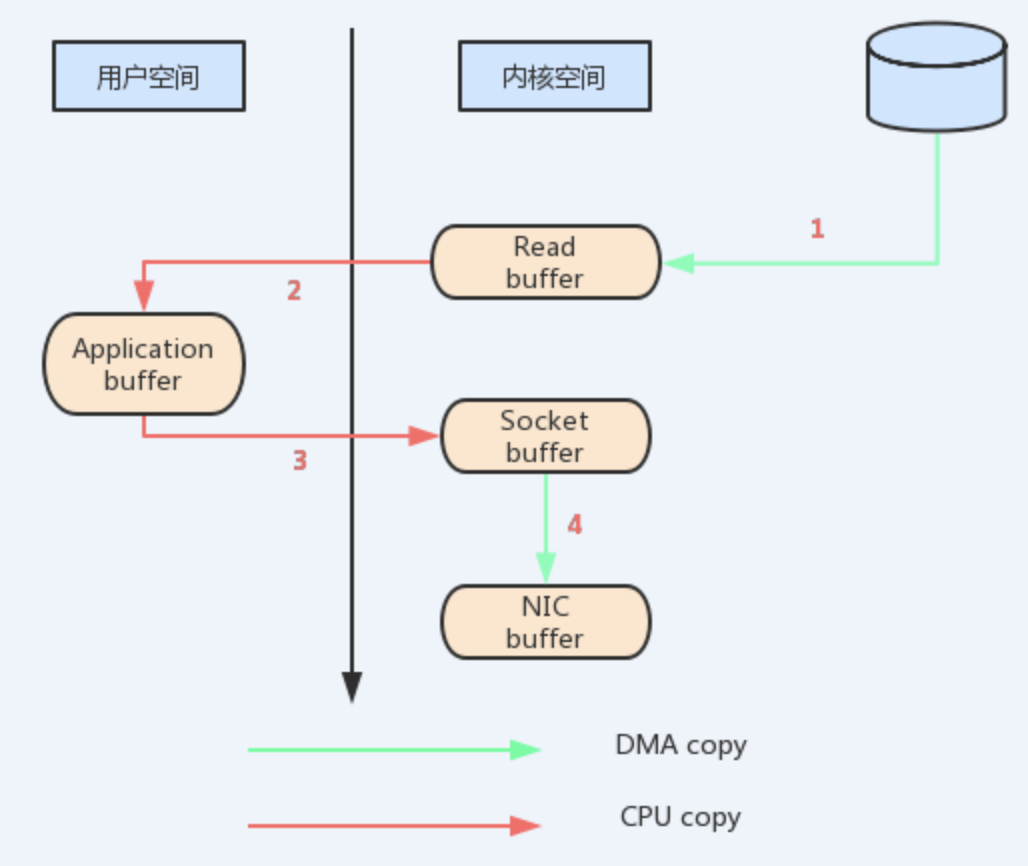
每次数据遍历用户内核边界时,都必须进行复制,这会消耗CPU周期和内存带宽。幸运的是,您可以通过一种称为“适当地 - 零拷贝”的技术来消除这些副本。内核使用零拷贝的应用程序要求__内核直接将数据从磁盘文件复制到套接字,而不通过应用程序__。零拷贝大大提高了应用程序的性能,减少了内核和用户模式之间的上下文切换次数
减少内核态到用户态的转换。
如果使用sendfile,只需要一次拷贝就行:允许操作系统将数据直接从页缓存发送到网络上。所以在这个优化的路径中,只有最后一步将数据拷贝到网卡缓存中是需要的。
kafka 的使用场景:
消息消费的时候,包括外部Consumer以及Follower 从partiton Leader同步数据,都是如此。简单描述就是:
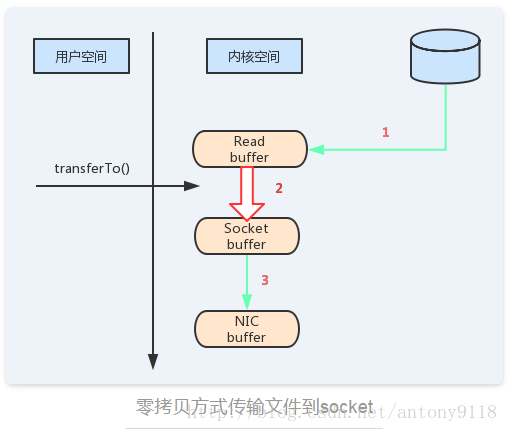
Consumer从Broker获取文件数据的时候,直接通过下面的方法进行channel到channel的数据传输。
java.nio.FileChannel.transferTo(long position, long count,
WritableByteChannel target)
2
也就是说你的数据源是一个Channel,数据接收端也是一个Channel(SocketChannel),则通过该方式进行数据传输,是直接在内核态进行的,避免拷贝数据导致的内核态和用户态的多次切换。
Kafka设计哲学上基本观点是认为数据时时刻刻都在流动,虽然数据在磁盘中,但因为基于内核进行交换,获得了数据近乎是存储在内存中的速度。没有必要放在用户空间中
Kafka作为一个集大成者的消息中间件,有三个很重要的特征:
- 分布式,为大规模消息打下基础
- 可以对消息进行__持久化__,默认会存放7天,意味可以重复消费
- 既支持__队列方__式,也支持__发布-订阅模式__
由于基于集群设计,又提供了非常强的__持久化和容错能力__。我们可以认为它是类似一个增加了消息处理能力的HDFS。
kafka从整体角度讲,所有数据存储被抽象为topic,topic表明了不同数据类型,在broker中可以有很多个topic,producer发出消息给broker,consumer订阅一个或者多个topic,从broker拿数据。从broker拿数据和存数据都需要编码和解码,只有数据特殊时,才需要自己的解码器。
consumer订阅了topic之后,它可以有很多的分组,sparkStreaming采用迭代器进行处理。生产者发布消息时,会具体到topic的分区中,broker会在分区的后面追加,所以就有时间的概念,当发布的消息达成一定阀值后写入磁盘,写完后消费者就可以收到这个消息了。
最后,想说,在中kafka里没有消息的id,只有offset,而且kafka本身是无状态的,offset只对consumer有意义。
2.kafka 如何做到1秒发布百万级条消息
kafak 提供的生产端的API发布消息到一个 topic 或者多个 topic 的一个分区(保证消息的顺序性)或多个分区(并行处理,不能保证消息的顺序性)。topic 可以理解为数据的类别,是一个逻辑概念。
维护一个Topic中的分区log,以顺序追加的方式向各个分区中写入消,每一个分区都是不可变的消息队列,数据由 k , v 组成,k 是 offset :一个64位整型的唯一标识,offset代表了Topic分区中所有消息流中该消息的起始字节位置。v 是就是实际的消息。
写入快: 1.顺序写入(随机写入会增加寻址过程),__批量__发送写入磁盘。 2.降低字节复制带来的开销,producer,broker,comsumer 三者使用共享的二进制消息格式。
KAFKA这种消息队列在生产端和消费端分别采取的push和pull的方式,也就是你生产端可以认为KAFKA是个无底洞,有多少数据可以使劲往里面推送,消费端则是根据自己的消费能力,需要多少数据,你自己过来KAFKA这里拉取,KAFKA能保证只要这里有数据,消费端需要多少,都尽可以自己过来拿。
写出快: 1.零拷贝 FileChannel.transferTo ,页缓存和sendfile组合,意味着KAFKA集群的消费者大多数都完全从缓存消费消息,而磁盘没有任何读取活动。
假设一个Topic有多个消费者的情况, 并使用上面的零拷贝优化,数据被复制到页缓存中一次,并在每个消费上重复使用,而不是存储在存储器中,也不在每次读取时复制到用户空间。 这使得以接近网络连接限制的速度消费消息。
2.批量压缩,即将多个消息一起压缩而不是单个消息压缩。
3.kafka 数据可靠性深度解读
kafka发送消息的时候支持:同步和异步,默认是同步的、可通过producer.type属性进行配置。
kafka的消息确认机制默认是 1 :leader收到会返回一个 ack 0的话是不返回任何 ack -1的话是所有的 follower 都与leader保持同步之后,返回zck
配置项:request.required.acks属性来确认消息的生产。
综合以上,可以检出 acks=0 和acks=1 的时候,都会发生数据丢失的情况。
解决办法:
针对消息丢失: 同步模式下,确认机制设置为-1,即让消息写入Leader和Follower之后再确认消息发送成功; 异步模式下,为防止缓冲区满,可以在配置文件设置不限制阻塞超时时间,当缓冲区满时让生产者一直处于阻塞状态;
queue.enqueue.timeout.ms = -1

针对消息重复:将消息的唯一标识保存到外部介质中,每次消费时判断是否处理过即可。
kafka 的消息保存在Topic中,Topic可分为多个分区,为保证数据的安全性,每个分区又有多个Replia。
多分区的设计的特点: 1.为了并发读写,加快读写速度; 2.是利用多分区的存储,利于数据的均衡; 3.是为了加快数据的恢复速率,一但某台机器挂了,整个集群只需要恢复一部分数据,可加快故障恢复的时间。
每个Partition分为多个Segment,每个Segment有.log和.index 两个文件,每个log文件承载具体的数据,每条消息都有一个递增的offset,Index文件是对log文件的索引,Consumer查找offset时使用的是二分法根据文件名去定位到哪个Segment,然后解析msg,匹配到对应的offset的msg。
kafka处理的数据量很大,可以说有多少个partition就有多少个leader, 所以简化一些管理逻辑,可以节省很多资源消耗。 kafka会将"leader"均衡的分散在每个实例上,可确保整体的性能稳定.
4.kafak 分区 leader 机制
kafka在引入Replication之后,同一个Partition可能会有多个Replica,而这时需要在这些Replication之间选出一个Leader。
Kafka将每个Topic进行分区Patition,以提高消息的并行处理,同时为保证高可用性,每个分区都有一定数量的副本 Replica,这样当部分服务器不可用时副本所在服务器就可以接替上来,保证系统可用性。在Leader上负责读写,Follower负责数据的同步。当一个Leader发生故障如何从Follower中选择新Leader呢?
Kafka在Zookeeper上针对每个Topic都维护了一个ISR(in-sync replica---已同步的副本)的集合,集合的增减Kafka都会更新该记录。如果某分区的Leader不可用,Kafka就从ISR集合中选择一个副本作为新的Leader。这样就可以容忍的失败数比较高,假如某Topic有N+1个副本,则可以容忍N个服务器不可用!
基于上面的分区 leader 机制,Producer和Consumer只与这个Leader交互,其它Replica作为Follower从Leader中复制数据。因为需要保证同一个Partition的多个Replica之间的数据一致性(其中一个宕机后其它Replica必须要能继续服务并且即不能造成数据重复也不能造成数据丢失)。如果没有一个Leader,所有Replica都可同时读/写数据,那就需要保证多个Replica之间互相(N×N条通路)同步数据,数据的一致性和有序性非常难保证,大大增加了Replication实现的复杂性,同时也增加了出现异常的几率。而引入Leader后,只有Leader负责数据读写,Follower只向Leader顺序Fetch数据(N条通路),系统更加简单且高效。
5.kafka 重复消费数据
kafka重复消费都是由于未正常提交offset,故修改配置,正常提交offset即可解决
消费者速度很慢,导致一个session周期(0.1版本是默认30s)内未完成消费。导致心跳机制检测报告出问题。
导致消费了的数据未及时提交offset.配置由可能是自动提交
问题场景: 1.offset为自动提交,正在消费数据,kill消费者线程,下次重复消费
2.设置自动提交,关闭kafka,close之前,调用consumer.unsubscribed()则由可能部分offset没有提交。
3.消费程序和业务逻辑在一个线程,导致offset提交超时
参考:https://www.cnblogs.com/huiandong/p/9402409.html
评论交流
say you want...